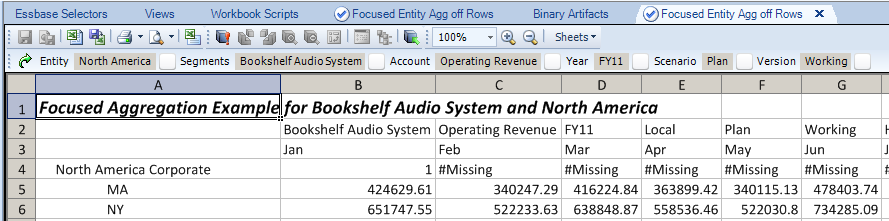
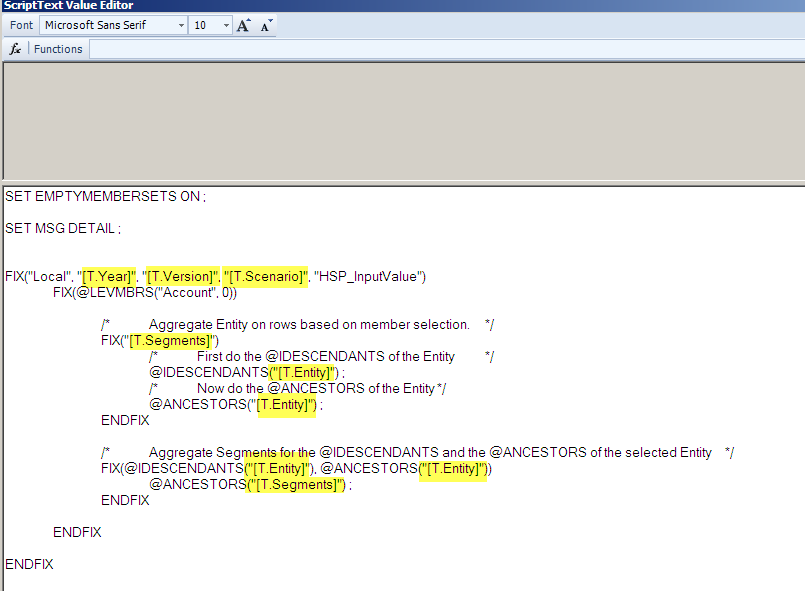
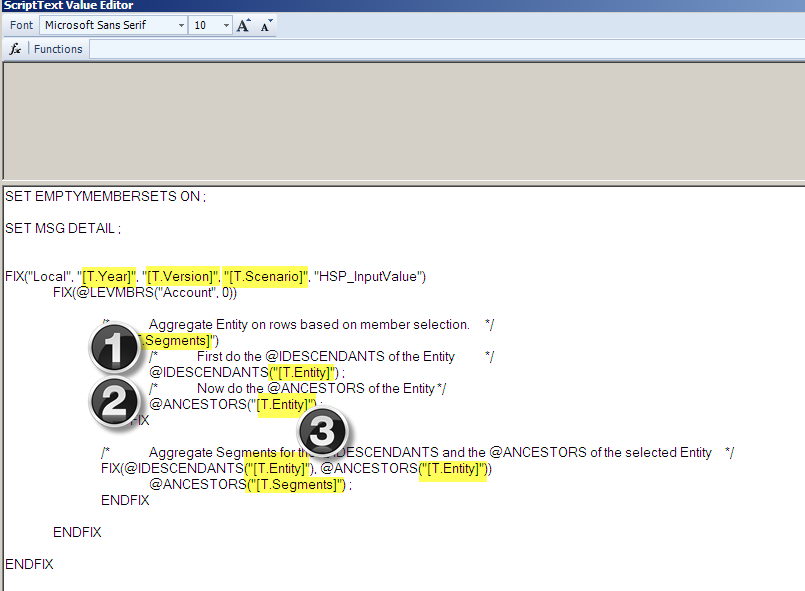
It all began one summer
It seems so long ago (2,770 days or 396 weeks or 91 months or 7.6 years – but who’s counting?) that I first put pen to paper – Yes, I did. Really. I’ve now moved on to word processors for drafts and am thus so 21st century. – and started this blog. And why the (re)counting? Because this little corner of EPM inanity has hit 300 posts. That’s an average of 39 posts of Stupid Programming Tricks, Compleat Idiot, Stupid Shared Services Tricks, Stupid Planning Tricks, and other sundry bits of EPM frivolity per year. I pity you for reading this dreck. Come to think of it, I pity myself for writing it at such a pace but on balance I think I feel worse for you.
But it is a landmark of sorts and an opportunity to reflect on why this blog continues when so many contemporaneously launched blogs are moribund or nearly so.
So yes, 300 posts and yet some of you are still here. Why?
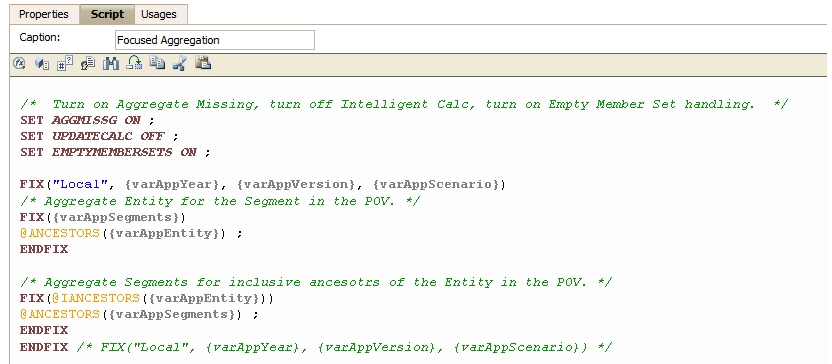
Don’t know much about Essbase/PBCS/Planning/FDMEE/etc.
I seem to be forever chasing Oracle’s EPM seemingly ever-expanding products – how do I do X, how did someone else do Y (and how can I “borrow” their approach), why doesn’t that !@#$ing Z work? Some of my fellow EPM practitioners seem to glide from tool to tool and solution to solution with nary a show of effort (Glenn, Celvin, TimG, TimT, Dino, and Pete I’m looking at each and every one of you. With envy.). I assure you that yr. most hmbl. & obt. svt never, ever, ever gets from A to B without a fair amount of pain. Solving the problem is always fun, staring at it (best of course when in front of other people, the more senior the better) in complete incomprehension not so much.
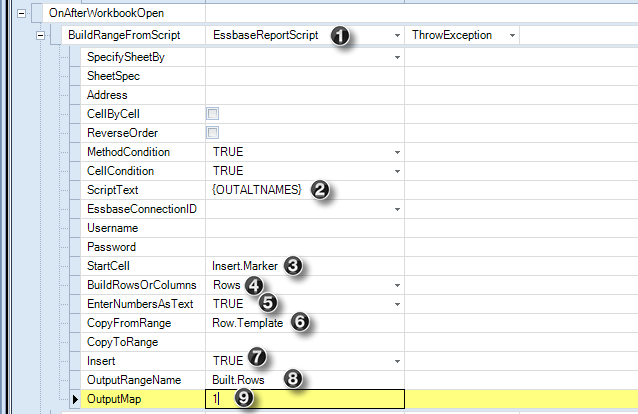
So are you this?

Or this?

Everything I've Got Belongs To You
There are the greats in this industry – any industry really – and then there are the rest of us. Is that so bad? We’re not the smartest guys in the room but at least we get to be in the room. Yes, I think I just insulted every one of you, Gentle Readers, but my point being that this blog’s primary purpose to help you and me get from A to B. Maybe the fact that you read work-related blogs (obv. not just this one), read EPM books, follow EPM geeks on Twitter, and read and post on messageboards means that in fact you’re amongst the smart set. Surely the smart ones use resources to solve their problems; surely the dumb ones don’t. See? I just rescued myself from having exactly zero readers. Hopefully.
All kidding aside, this blog as it exists today would be pointless without you. Thank you for putting up with what has been described as an idiosyncratic (read: long winded with detours into obscurity) approach. I hope you take the time to click on all of my laboriously-gathered links. Goal one of this blog: make you better EPM geeks. Goal two of this blog: make you all wish it was 1967 aka peak American popular culture as it’s a giant wasteland after that. Let’s turn the clock back. At least you’ll appreciate what your parents or grandparents (or in some cases great-grandparents) grooved to.
I’ve got your number
Google (Blogger and Google Analytics) is funny and by funny I mean inconsistent.
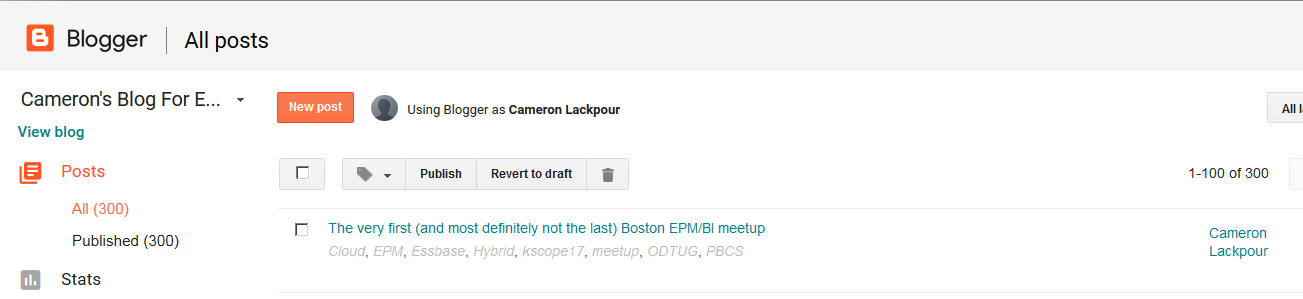
Here’s Blogger’s numbers:
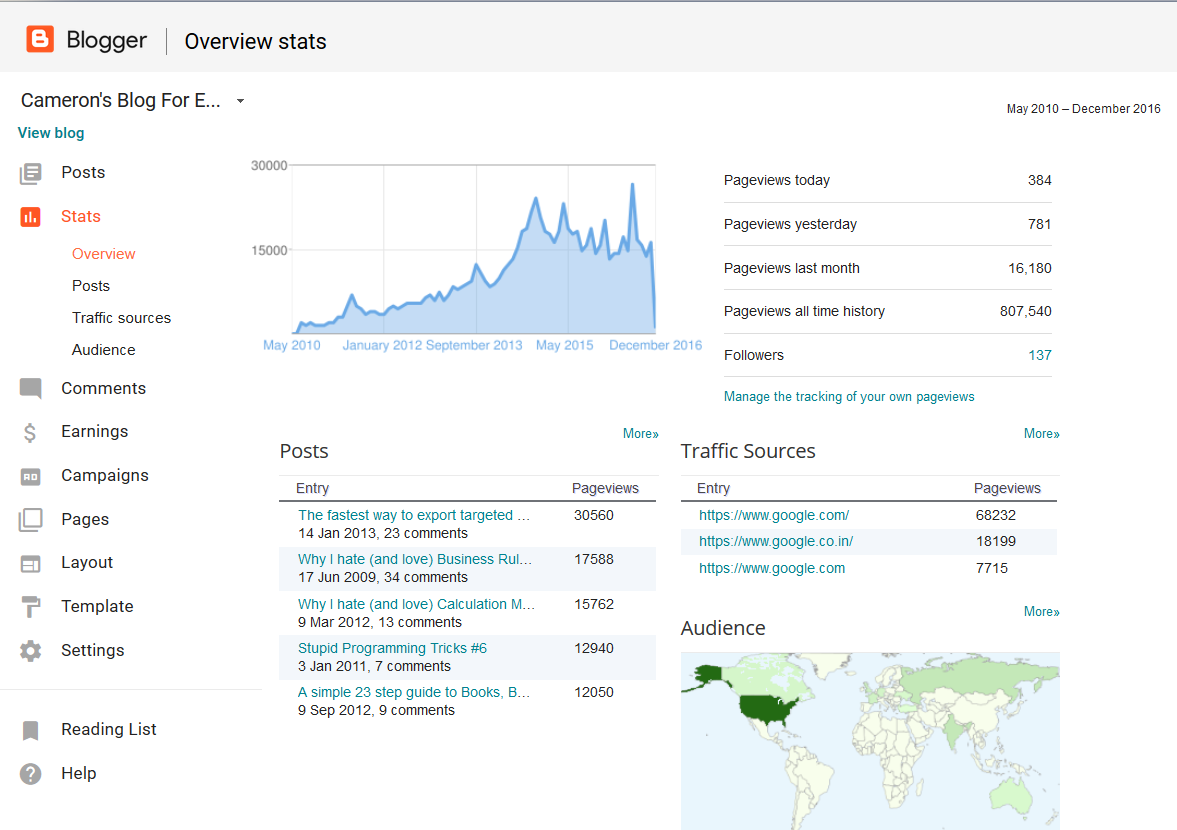
Huzzah! I’m closing in on a million page hits.
And then there’s Google Analytics:
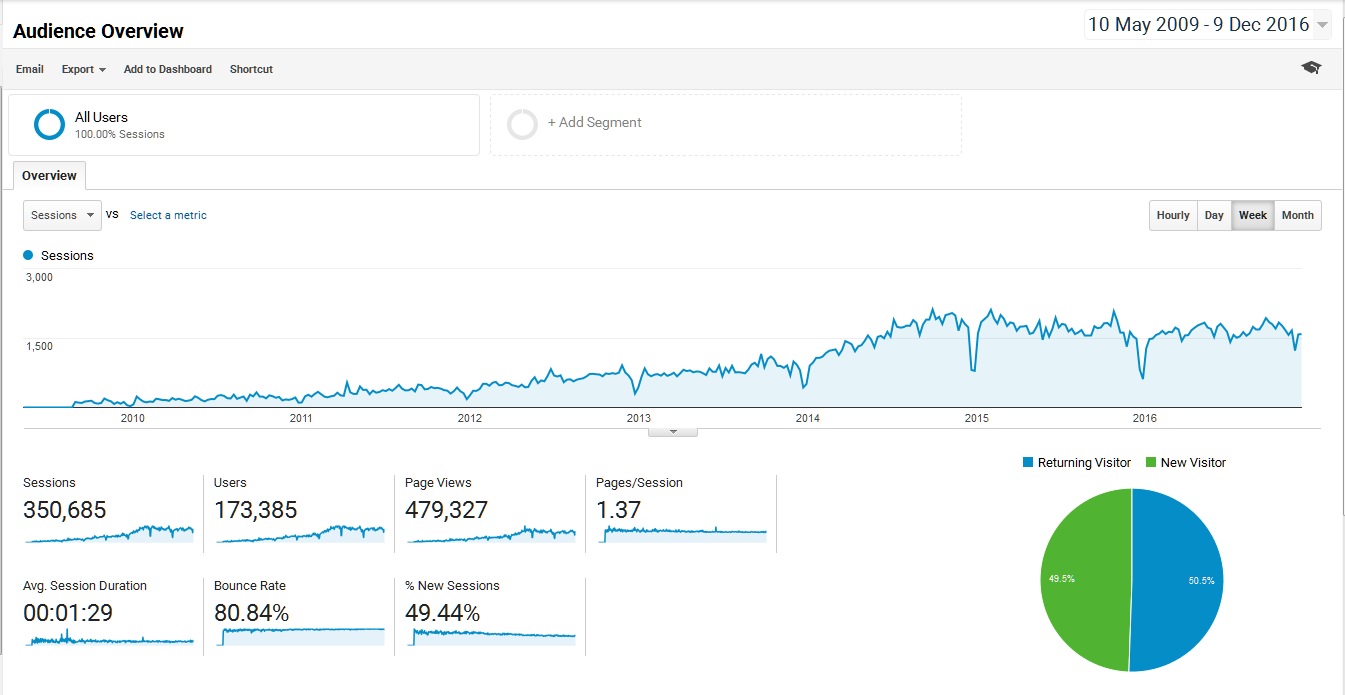
Not-huzzah because it’s telling me that I’m closing in on half a million page views.
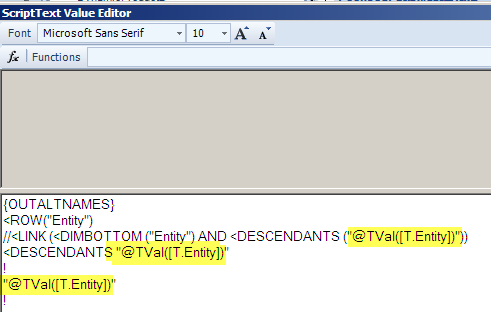
It’s a riddle
A couple of interesting notes about the above:
- People don’t read this blog around Christmas. Not a huge surprise there.
- My readership is going – slowly – down. Why?
For the first, it’s nice to know that people have lives.
As for the decline (and it is real, alas) is I think based on two things: number of posts per year (I hit my high in 2014 of 52 posts and readers vs. 40 the year after – less new content = less readers) and competition from other posts as well as Twitter and other social media. I haven’t tried to count the number of EPM-related blogs extant today but it surely has to be about 50. When I started it out the number was more like 10 although as noted most of those are dead, dead, dead. YouTube, Facebook, and Twitter are yet more avenues for those who want to learn.
Or this blog sucks and is getting worse all the time. You decide.
Why shouldn’t I
I like to think that actually the blog is getting better. I’ve purposely hit on a combination of series posts such as the Compleat Idiot series on Planning in the cloud, Programming Stupid Tricks for unrelated Essbase, Planning, whatever-they-are tips and tricks, and community outreach posts such as live (sort of) blogging of Kscope, OpenWorld, and now meetups.
You may have noticed that I’ve switched to a longer and more in depth approach in my Compleat Idiot cloud series. There’s an awful lot to learn about Oracle’s cloud products. Lots of innovation, yes, but also lots of work learning the tools and then keeping up with them. I can’t think of how to do this except through this detailed way as so much innovation is coming out of the movement to the cloud. Love the cloud or loathe it, money is being poured into the products in a way that simply hasn’t existed before. That means the products change and expand constantly and that likely means the Compleat Idiot series won’t either. That also means my life won’t get a lot better because some of these posts are over 50 pages when written in Word. Ouch for both you in the reading and me in the writing.
While solutions to problems are what we’re all after, there is more to life and a career than code. I’ve used this blog as a soapbox to encourage you in the strongest terms to get involved with our little community. As an example, my involvement with ODTUG has utterly transformed my professional and personal life. If it happened to me, it can happen to you. Grasp the ring. Reach. Blow your horn.
Where I can, I’ve tried to also impart what little wisdom I’ve picked up in 20+ years of consulting in a 25+ year EPM so-called career. Sometimes I shake my head at the folly of others when it comes to solutions (hubristically complex), code (ugly, hardcoded, slow, wrong – sometimes all four at once), and even social interactions (Is there anyone more awkward than a geek? Thought not.) and then realize that I almost certainly did the same thing at one point or another. Smart people learn from others’ mistakes. Think of this as a plea to be smart and occasionally listen to me as I’ve made every mistake there is.
The other bit of advice I’d give you is don’t be afraid to be a contrarian. That of course doesn’t mean you’re always right, but reflect on why people say what they say. Is a technical recommendation for the good of customer or is for the benefit of the speaker? Is product X the solution that everyone follows because a vendor is pushing it or would some other simpler and cheaper approach work just as well?
In a word:

Try to See It My Way
What about the “hacking” in the name of this blog? Hacking can mean all sorts of bad things and that’s what villains do. Good hackers are more interested in taking an ordinary tool (but so cool) and doing out of the ordinary things in a geek chic way.
To that end, I’m going to try to share with you some of the dumb things I’ve done and how you don’t have to do them, how to make Essbase do things it “can’t” do, and generally make Essbase dance.
Lastly and most importantly, I’ll also share code/techniques/approaches. I welcome your comments (constructive please, I have an average ego and it is bruised when pummeled) and most of all your suggestions for improvements. I’ve never written a piece of code that hasn’t been improved through examination by a fresh set of eyes and as a consultant if I can’t fix where I wrote it, I’ll make it better next time.
And, despite the title of this web site, I won’t limit the scope of my postings to Essbase. I’ll include anything else that touches Essbase, from Planning to Dodeca, to who knows what.
That, for good or ill, is pretty much what this blog is all about. Through the passage of time I’ve forgotten about “geek chic” and shall henceforth casually drop it into conversation.
All kidding aside, I’ve tried very hard to live up to my vision of education and outreach and I think on balance I’ve managed to do it.
Watch what happens
So where does this blog go from here? Will there be another 300? Will I lose my ever-lovin’ mind and actually do this again? Maybe.
So long as I’m involved in this little industry, I feel I have no choice but to keep learning. Whether that’s through this blog, speaking at conferences, writing books, or in some other completely-monetarily-uncompensated form, I’ll keep on learning and sharing. One day, hopefully not too (actually, yes, hopefully given what that entails) long from now, I’ll retire and this blog will come to an end. I’m not dead yet and I’ve got a lot of livin’ to do so expect more of Cameron in one form or another.
Because of you
So yes, this blog exists because I use it as a mechanism to teach myself but making it public with a readership that rounds down to zero would be pointless. Thank you for your support, your comments and corrections, and your continued readership.
Call me
Want to see a topic? Have a question (hopefully) answered? You can reach me care of this blog or via Twitter or via LinkedIn or reach out to me in person at meetups, Kscope, and Open World.