It is no secret
I have no love for Essbase Load Rules. Mostly because I have comprehensively, completely, and utterly tied myself into knots using them. And I should be clear about this – they are dangerous in my mind because it is easy to crude ETL in them that you (or at least I) will promptly forget about. When it comes time to change things, or data changes, it is a complete Pain In The You-Know-What to figure out what was done in the rule. Yes, they were Hot Stuff when invented, but that was almost 20 years ago (yes, really) and it is time for their closed nature to go, go, go. Well, at least that’s my opinion. I don’t really hate the things, but I do think that ETL via Load Rules is just asking for trouble and I wonder why there is no other lightweight way of sending data in an automated fashion. Read on, gentle reader (all three or four of you), and yr. obdnt. srvnt. will reveal all.Four exceptions to Load Rules
Actually, there are at least four different ways of sending data to Essbase without using Load Rules.Load in free form
Have you ever locked and sent (BSO and the classic add-in)/sent (ASO and the classic add-in) or submitted (BSO or ASO and Smart View)? Then you have used Essbase’s free form data format and yes, you can load it directly into Essbase sans Load Rule. Want an example? Take a look at CALCDAT.txt in Sample.Basic. It is a free form data file with level zero and consolidated data values. Why Arbor (yes, it is that old) did that, I cannot say, but they did.Load via ODI
ODI has an option to load data directly into Essbase without a Load Rule. However, there seem to be lots of issues with that approach (go on, search for it and you will note that most ODI practitioners use a Load Rule because it is cleaner) and of course you have to buy into ODI in the first place. I am a huge fan of the tool but its learning curve has a very cliff-like look to it.Load via Studio
Essbase Studio is a great way to explore data, model it, and ultimately express it in Essbase. And yes, there is nary a Load Rule to be seen in the tool. But, at the end of the day, Load Rules are used to get metadata and data into Essbase. I am inclined to cut Studio a break as Studio developers don’t so much as dirty their fingernails with Load Rules. Nevertheless, programmatically derived Load Rules (that use ultra-secret API calls) are still part of the equation as they are generated by Studio so it is still tarred with that brush.Load via MaxL
Did you know that MaxL allowed you to load data points to Essbase? No? Did you know import data did this? It’s really pretty easy.Before
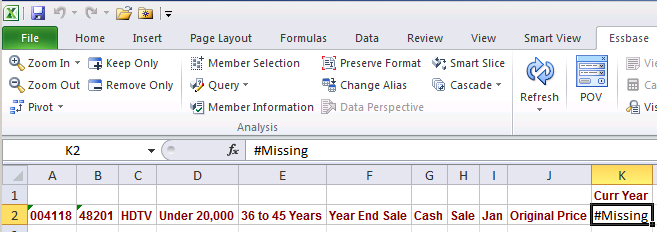
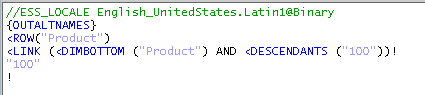
MaxL

After
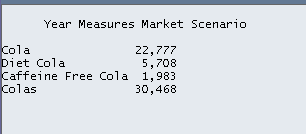
Pretty cool, eh? You will note that this is essentially a free form data load which is the same as a submit (see, I am divorcing myself, reluctantly, from the classic add-in in every way and manner) from the Microsoft Office tool of your choice. But this approach isn’t really suitable for more than a small amount of information.
Four exceptions, but none necessarily right
Free form simply is not a practical solution, ODI is a great tool, but you have to be 100% committed to it and it has its caveats, Studio, while cool, is also not a simple solution and it resolves to the dreaded Load Rules in the end, and loading small bits of data via MaxL is interesting, but ultimately not practical.What is needed is a lightweight way to load data, from SQL, without any of the above approaches and of course without Load Rules. How oh how oh how can this be done?
HyperPipe to the rescue
Well, I didn’t write it
I was whining/complaining/ranting (I can do all of this at the same time and it is difficult to distinguish one from the other) to Jason Jones about Load Rules (yeah, this is one of the biggest bees that buzz around my bonnet) and he said (NB – Artistic License ahead), “Really? You’d like to load data to Essbase without using Load Rules? Give me a couple of days.” And so it was. It is great knowing people who are smarter than you.So what is it?
It’s a command line way to load from files or SQL to Essbase. Note the words that are missing from that sentence – Load Rules. <insert evil laugh> This example will show loading to MVFEDINTWWW, aka Sample.Basic step by step.Data in SQLOh, did I mention that the Merant ODBC drivers are no more? What you see below is the open source H2 Java database. Did I mention the client is running on a Mac? It made me laugh out loud.
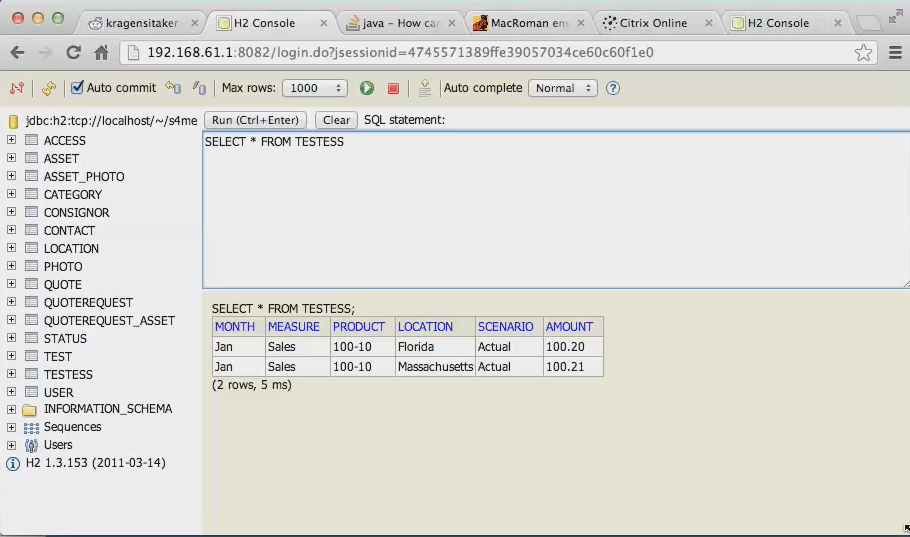
I should note that the above is not implying a Mac version of Essbase, but instead shows that with a web application orientation, one can access data and processes across platforms and machines.
Data target
Here’s the data target. Jason has not yet made the switch to Smart View. I understand his pain.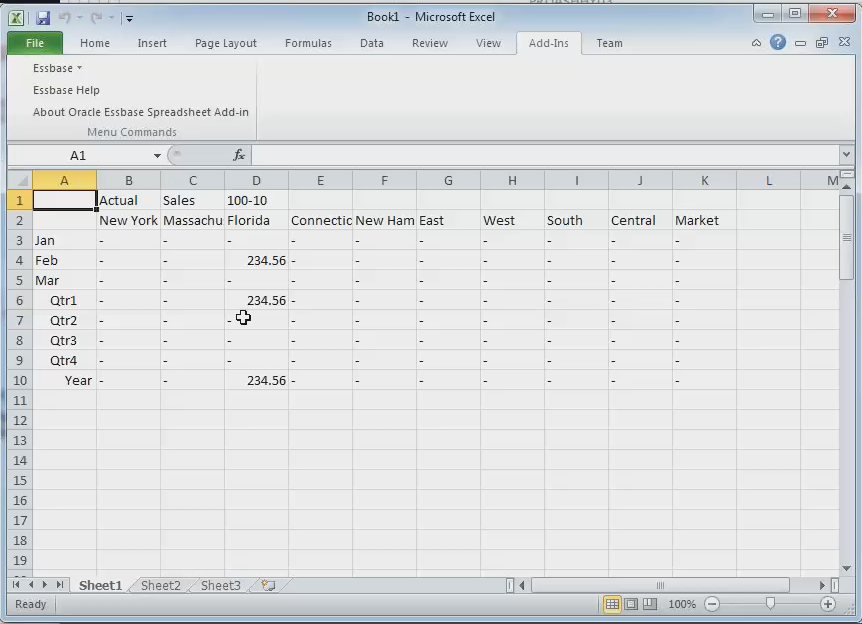
Where does it run?
Jason is a Java guy, so the code to run this is in the hyper-pipe (HyperPipe? hyper-pipe? Tomatoe, tomatoh) jar file through the bash Unix shell.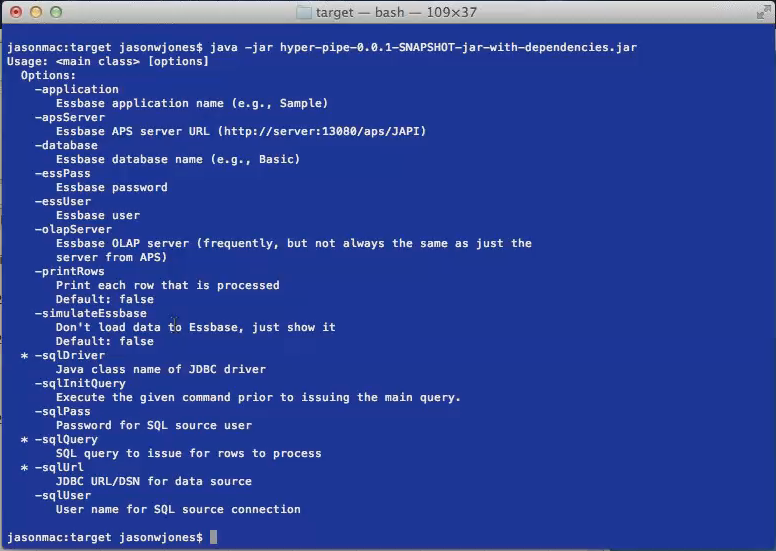
Are you catching all of the properties? Just about everything one could possibly think of wrt a data load to Essbase. You can read the screen as well as I but I draw your attention to two parameters.
sqlDriver
JDBC to the rescue, ODBC goes bye-bye. Neat, huh?sqlInitQuery
Want to manipulate columns and data? Do it in SQL, as Zeus declared on Mount Olympus. At least I’m pretty sure he said that in Clash of the Titans. Just watch the good (original) one -- I think me mentions it right after, “Release the Kraken”.You may fire when you are ready, Gridley
And that’s it. A load to Essbase, from SQL, with Load Rules being conspicuously absent. <insert big grin>Data in Essbase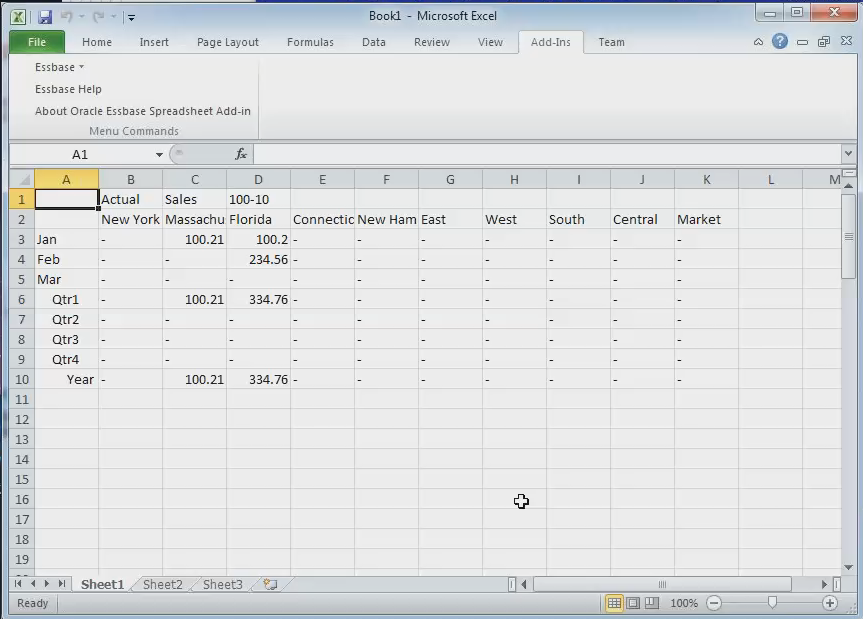
How does it work?
Jason described it as akin to the MaxL data load process. And that is all I know of it as I am no Java programmer. However, the good news is that Jason is going to release this as an open source project so you can download it and tear it apart. Have fun.So is that the end of Load Rules?
Alas and alack, no. They will be around, quite possibly forever (if you define forever for as long as there is an Essbase, then yes, definitely forever) as there are simply too many people with too much code in them.On the other hand, Oracle took the bold step of giving the chop to Hyperion Business Rules to be replaced in 11.1.2.2 onwards with Calculation Manager and the same is true for the Classic Excel add-in for Essbase, so there is hope.
As of this writing, Jason has not released HyperPipe but as I noted, he is an open-source kind of guy. Contact him via his blog and look there for a much more in depth review of the tool.
And let me also give a hearty thanks to Jason for figuring out how to do this. Now if only a certain absolutely humongous software company takes this concept and runs with it. <insert the biggest grin thus far> As the immortal Robbie Burns wrote, “Ah, but a man's reach should exceed his grasp, Or what's a heaven for?”
Be seeing you.